TAMUhack X🔗︎
My Second Hackathon🔗︎
I regretted not assembling a team last year, so I tried to find one this time. Unfortunately, most of my friends were either too busy studying or had already joined a team. I decided from the beginning that I did not want to focus on one of the challenges this year so that we could get a head start planning. Plus, many of the challenge projects end up looking very similar. I wanted to make something unique.
This hackathon occurred a few months after ChatGPT revealed GPT-3 to the world. I wanted to create an LLM-powered application. We considered building an app that would ingest documents, but we decided to start with something more achievable. I learned from last time that 24 hours is really not as much time as it sounds like. My team decided to build a virtual assistant.
But how would we distinguish ourselves? I was sure that other teams were also going to be building something with ChatGPT integration. We decided that our assistant would have text-to-speech and speech-to-text capabilities. We also wanted to integrate it with APIs that would let the assistant access the user's data.
Meet Warvis🔗︎

Generated by DALLE-3
We named our virtual assistant Warvis: Jarvis on the Web. I decided to focus on the backend while my teammates focused on the frontend. I found a library called LlamaIndex that would allow an LLM API to interface with various data sources, including Google APIs. If I could set up a Google API key, I could let Warvis access my email, my calendar, my notes, and more.
Data flows through Warvis in an interesting way. When the user makes a query, that is sent to GPT-4 along with a list of the types of information that the assistant has access to. If the LLM decides that its response could be enriched by some of the available information, it requests it instead of responding directly to the user. That request is sent to my computer, which then completes the request to the Google API, parses it, and delivers the relevant information back to GPT-4. It can repeat this process multiple times if information is needed from both the user's email and the user's calendar, for example. Once the LLM sends its final response, the user receives the message. The interesting part about this is that the LLM can do more than simply access information. It can also write calendar events or write emails with the Google API. This was a very interesting project to get working.
I started with my calendar. It was actually pretty simple. Calendars are relatively sparse in information, so I was able to send the entirety of my schedule in the near future to the LLM. It could answer questions about my schedule and also schedule its own events when the user requests. Email, however, was another story. Emails are incredibly dense. Think about how many emails you receive each week. Even just sending the titles to the LLM can easily exceed its context limit, or the maximum number of "tokens" that it can process at a time. Sending emails was easy, but finding emails relevant to the user's query was difficult. If I were going to continue this project, I could download the contents of the user's recent email to my machine into a vector database. That would allow the LLM to perform semantic searches on the data, essentially allowing it to find relevant emails without having to read them all. However, I didn't have time to implement this functionality.
Another feature that I added is called ReAct prompting. ReAct prompting is a method of sending specifically formatted instructions to the LLM to enhance its reasoning. This process has four stages:
- Thought: The LLM analyzes the user's query and decides if a response would be enriched by retrieving additional information or performing an action on behalf of the user
- Action: The LLM sends a request to the most relevant API
- Action Input: The LLM decides what parameters the action needs
- Observation: The API responds with the requested information or the status of the requested action
- Repeat: If more information is needed, repeat the Thought-Action-Observation sequence
- Answer: The LLM responds to the user
This is a typical message that would be sent to ChatGPT to begin the conversation:
This is what a typical conversation would look like:
Making it Functional🔗︎
While I was connecting the APIs, my teammates were working on the UI. We started out with Flutter, but we unfortunately had some issues getting it functional.
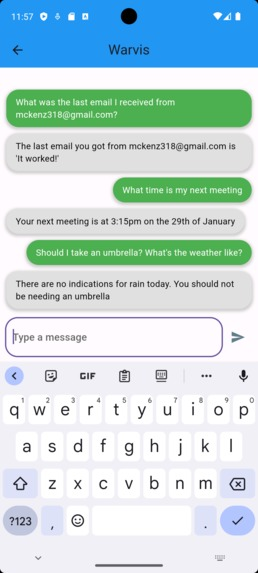
We decided to make an interface in pure HTML for the demo. It wasn't very pretty, but it was functional!
Lessons Learned🔗︎
There aren't very many prizes at these hackathons. The point is really to meet new people and build something cool. That was my goal and I succeeded. It may not be pretty, but the functionality is there, and we learned some new skills along the way. I also did a better job this time of delegating and assisting with issues as they came up. My teamwork skills are improving, but I'm still looking for new opportunities to test them.
Demo Video🔗︎
Links🔗︎
View Code On GitHub View Entry On Devpost View Competition Website