AgTern🔗︎
The Problem🔗︎
Many college students struggle to find and apply for internships. It can be difficult to find internships that are both relevant and interesting by browsing dozens of company websites with different layouts, each with a separate application process. To solve this problem, I have been working on a team project called AgTern as a member of the Aggie Coding Club. We endeavored to streamline this process by creating an application that would collect data from thousands of internships across the web and present it with a user-friendly interface. This would eventually become one of the most ambitious projects I had ever worked on. My contributions to this project have been substantial. It presented a myriad of technical challenges that I have enjoyed coming up with carefully architected solutions for.
Humble Beginnings🔗︎
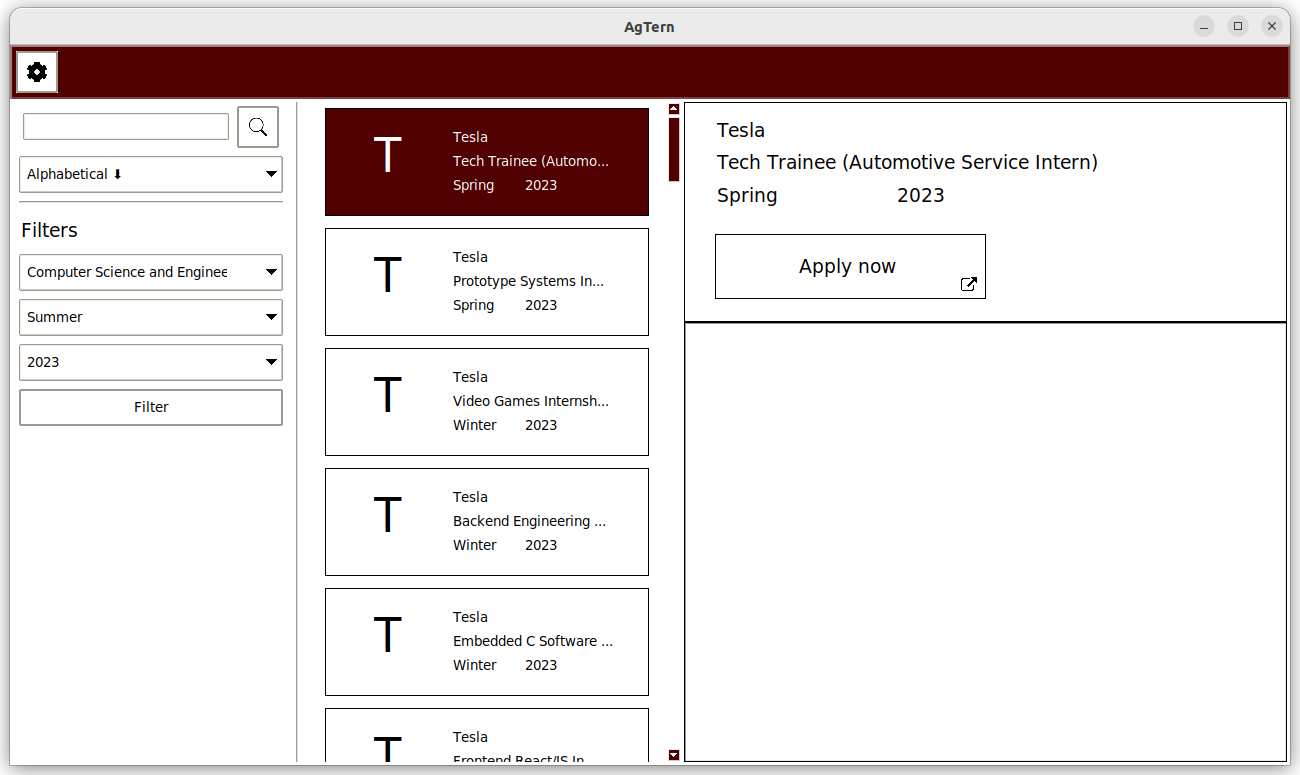
From the beginning, we knew that this was going to be a web scraping project. Most of the team including myself had some experience with web scraping, but none of us had ever attempted to collect data on this scale. We needed to come up with a generic solution that would work with a variety of websites. Each website's code is structured completely differently, and each company publishes different data about each internship. Our first approach was to create a Python script that would perform the web scraping on the user's machine. This script would control a Chrome web browser to navigate to each company's website and collect internship data. We created a GUI with Tkinter to display the results.
A Standardized Solution🔗︎
Our first problem was standardizing the method of collecting data from each website. At first, there was a file called
companies.csv to hold the URLs of each company's internship page.
| companies.csv | |
|---|---|
This solved the problem of having to hardcode the URLs into the script, but the main problem was that we were still having to write a new script every time that we added a new company. These scripts were brittle, meaning that they were easily broken by updates to the website's layout. We needed a more robust solution.
I investigated how to solve this difficult problem. There are many ways to extract the text that we wanted out of the
HTML code. Regular expressions would not work because the HTML uses a
context-free grammar; it is not a
regular language.1 I always strive to find the simplest, most
straightforward solution. Some HTML elements have an id, a name, or a class attribute that identifies them. But
the most flexible way to standardize data collection is to use XPaths! XPath is an expression language to query XML
documents,2 but it can also be used for HTML. With XPaths, elements can be identified by several properties:
attributes, their position relative to other elements in the DOM, the text inside them, and more. These expressions are
relatively simple to write, easy to parse, and fast to execute. And the most important property of these expressions is
that they can effectively match multiple elements. This makes it possible to store a single expression to retrieve
the titles of all internships on a page, for example.
To contain this new data, I designed a JSON config file called scraping_config.json. This file contained the name of
each company, the link to the internship page, and a list of actions to perform on the page
(related PR). Each of these action names maps to a Python function and can
perform actions like scrolling to load more results, clicking buttons, and following links. The configuration file below
defines a web scraping job that starts on https://example.com, collects all the links to the internships on the page,
navigates to the page for each internship, and collects the title and apply_link contained within. These
configurations are extremely powerful. At this point, we were ready to begin scraping thousands of internships!
Reevaluating Our Architecture🔗︎
After creating a universal configuration format, the next problem to solve was the architecture of our program. Now that we were beginning to scrape thousands of internships, it would take a long time to complete. It no longer made sense to perform all of this work on each user's machine. This also presents an ethical issue since we would be creating excess load for the websites that we were scraping. There is also the risk that these websites block our users if scraping is done too quickly or too often. We decided to migrate to a client-server architecture where we would run periodic scraping jobs on a server. The internship data would be stored on the server and queried by clients. We considered keeping the Tkinter UI, but it was clunky to navigate and difficult to style. I decided to create a web app using Angular. This would allow us to design a more user-friendly interface and style it with (S)CSS. This also has the benefit of streamlining the user experience. Instead of having to download a program, our users can now simply visit the website.
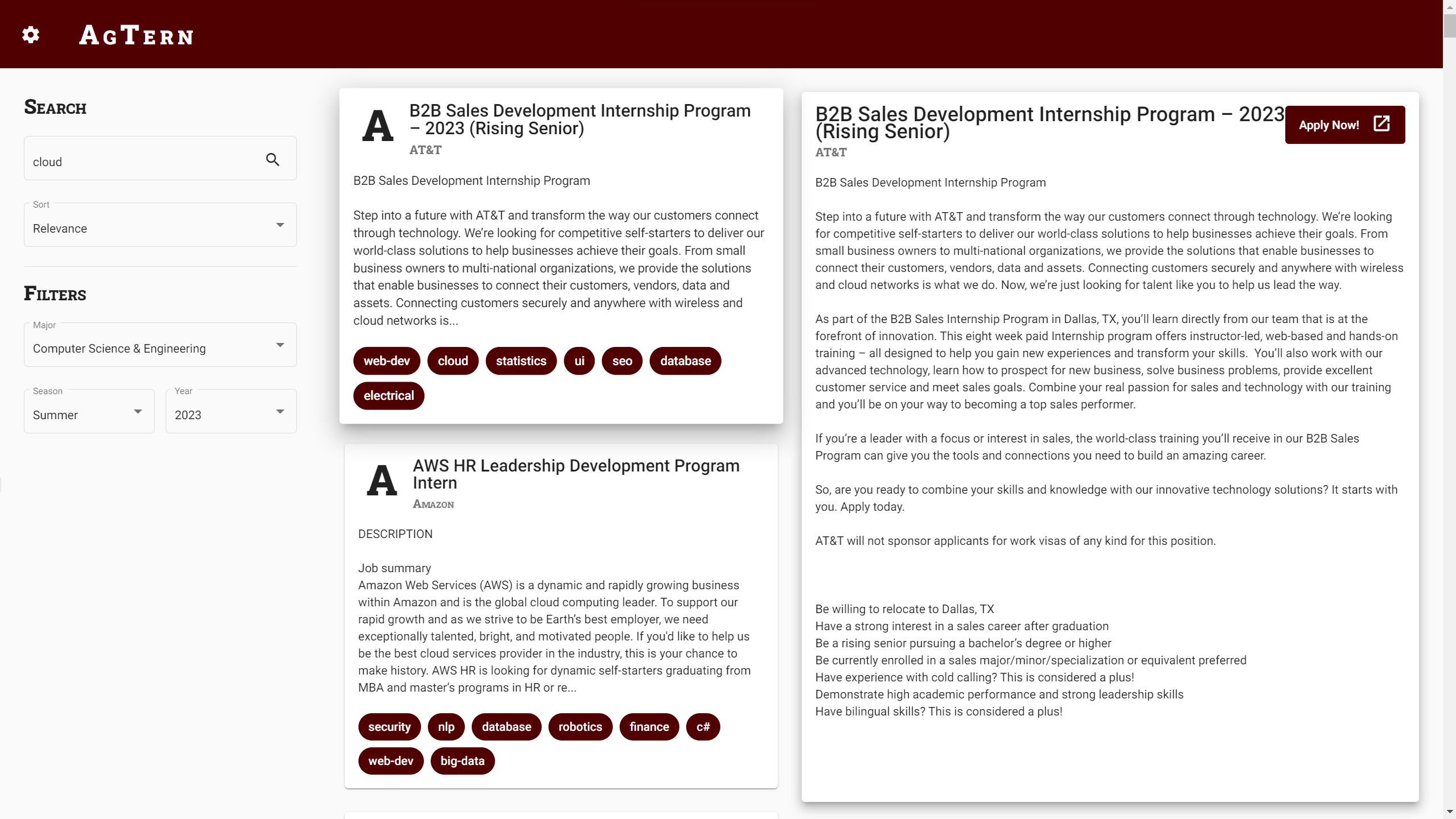
Immediately after this migration, a lot of work was done behind the scenes to improve the resiliency of the web scraper, including standardizing the internship model so that the data can be stored in a relational SQL database. At first, we used SQLite, but we eventually migrated to PostgreSQL to improve performance (related PR). I also implemented search functionality and pagination to allow the user to find internships according to filters (related PR). Eventually we hope to be able to provide personalized internship recommendations.
Scraping At Scale🔗︎
Although the web scraper was working well, there was still friction in our development process. The
scraping_config.json file was very powerful, but it was also verbose and difficult to validate. The system itself was
working smoothly, but it was difficult to add new companies. It was also difficult to validate that the XPaths were
written properly until the scraper was run. I solved these problems with two new features: a new configuration system,
and AgTern DevTools.
Part of the problem with the old configuration file was that it was doing too much. Like a function that grows too
large, the configuration was difficult to read due to the complexity. Our data was mixed with the actions that we wanted
to perform on it. The system completely fell apart when we wanted to customize how a single company's data was
processed. I wrote several band-aid solutions by adding parameters to the scrape action that modified how scraping was
performed. That function had many features, but it was difficult to manage when multiple parameters were specified.
It was too generic, ironically making it less flexible through the process of standardization. My new
solution was to separate the configuration into two files: a company-specific JSON file and companies.py. Both of
these files are as simple as possible, with the config managing data and the script handling behavior.
| companies.py | |
|---|---|
This system is the most flexible because it allows us to use raw Python when needed. We can use control flow to scrape multiple sets of pages, retry actions when they fail, and manually post-process our data. Both files are easy to read and write. The JSON file can be easily validated with a schema when editing in an IDE and code completion can be used in the script file.
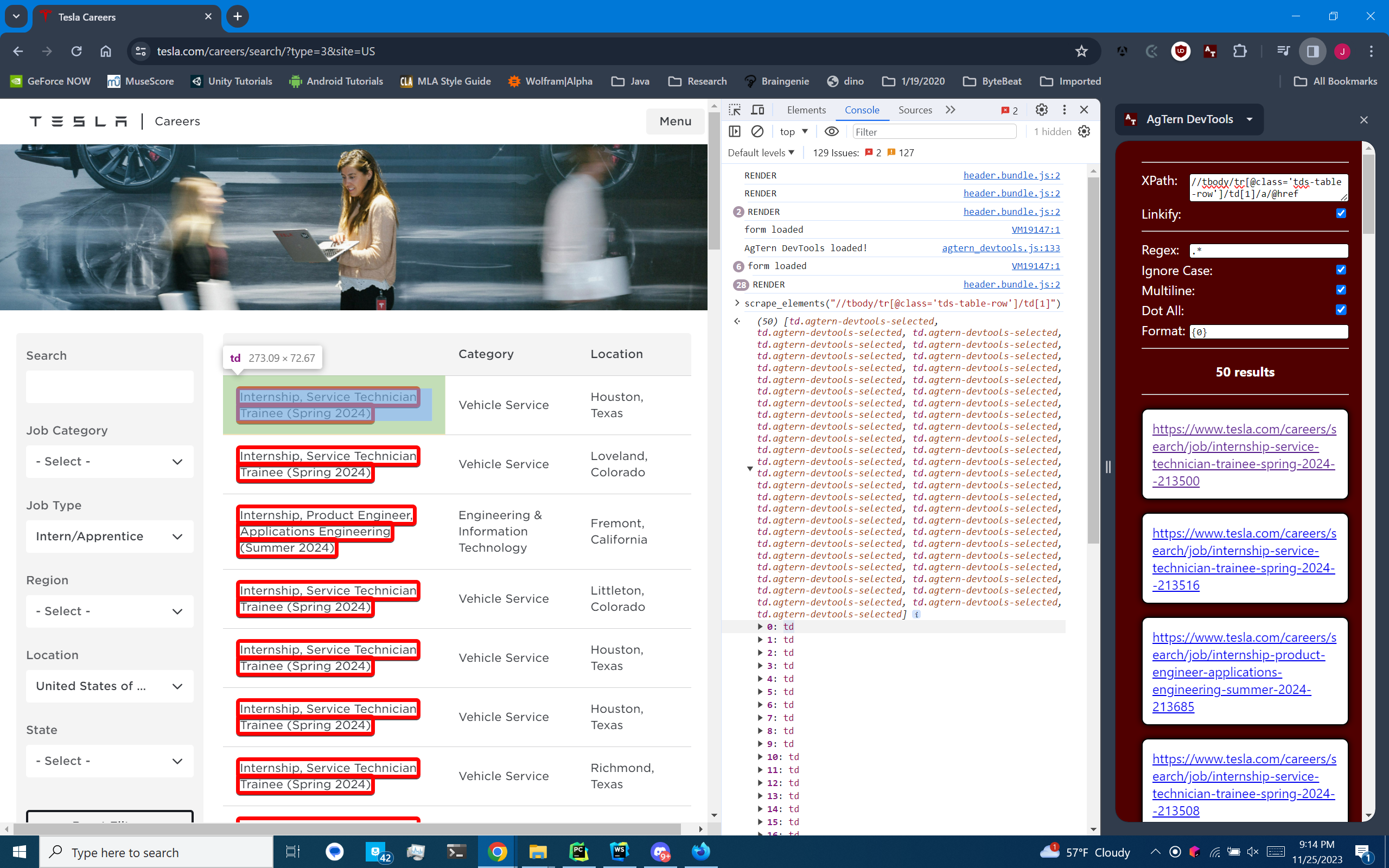
For the second problem of validating XPaths, I created the AgTern DevTools Chrome extension (related PR). This extension adds a sidebar to Chrome that allows you to retrieve a list of strings off of the current page using a handwritten XPath. It highlights matched elements, it supports post-processing with regular expressions, and it can be used at the same time as Chrome DevTools. This extension was the final piece of the puzzle to make our web scraping system as developer-friendly as possible.
Deploying AgTern🔗︎
With all of our new systems in place it was time to make our project available to the public. Since migrating to Angular, the project was hosted on an Ubuntu server. Each time that we wanted to push changes to the server, I would log in to the server, stop the program, pull the new code, and start the program again. This was not only a tedious process, but it is also a security risk. Ideally, no one would need to have direct access to the server in order to manage it.
I researched different ways to automatically deploy our code when changes are made in the code repository. The solution that I came up with was to use FluxCD, a Kubernetes operator that watches a Git repository for changes and applies them automatically. The main benefit of using this approach is that it follows GitOps principles,3 meaning that the repository is the single source of truth. The entire configuration of the server is now stored with the code, allowing us to quickly spin up a new server if the old one fails catastrophically. Secrets can even be stored in the repository using Flux's Sealed Secrets. A secret key is stored on the server to decrypt these secrets when they are pulled from the repository. This approach is also modular, meaning that we can update different components independently (like the web scraper or the database).
This system is great, but recently we have run into problems with performance on the server. Since this is still an unfunded community project, we have been using free credits to run the server. We are currently looking into ways that we can host the site ourselves to reduce costs.
What I've Learned🔗︎
This project was a very interesting one, and it is still in progress. Managing code complexity is one of the most important things that I learned from this project. By trying different solutions, refactoring, and testing, I learned how to structure my code in such a way that is more maintainable from the beginning. I am able to more effectively visualize different architectures before I take the time to implement them, greatly reducing trial and error. I learned how to work with a team to set goals and meet deadlines. We had many interesting conversations over the last few semesters about how to solve each problem that we faced. These soft skills will be arguably more important than the technical skills that I gained from the project.
Looking Ahead🔗︎
The future is bright for AgTern! We have come a long way in the past two years, but there is more work to be done. We have implemented an account system on the website, but we have not yet implemented personalized recommendations, arguably one of AgTern's most attractive value propositions. Our search algorithm is also very simple, and we hope to improve it using partial string matching and possibly semantic search. We have begun to develop metadata curation algorithms using natural language processing, but we are still researching efficient ways to store and search this data. It is possible that we can use large language models to aid in tag extraction from internship descriptions.
My Pull Requests🔗︎
- Merge Upstream
 Implement Scraping Algorithm!
Implement Scraping Algorithm!- Fix PyCharm Run Configurations and add PEP8 Style Checking
- Remove Brendan's info from config.ini
- Implement Advanced Scraping Algorithm
- Scrape all Tesla internships and integrate web scraper with FastAPI & SQLAlchemy
- Scrape more companies
- Migrate to Angular
- Add Auto-Generated Angular API Service
- Add Search Functionality
- Merge Dev into Main
- Merge Scraping Overhaul Phases 1 and 2
- Overhaul Scraping Backend
- Create AgTern DevTools
My Issues🔗︎
- Create Web Scraping Algorithm
- Give everyone write access to the AgTern Project
- Convert Code Directories into Python Packages
- Create AgTern Wiki
- Add Logger
- Update PyCharm Run Configurations and Add PEP8 Style Checking
- Clean Up requirements.txt
- Create config.ini with default values if it does not exist
- Create GitHub Action to verify PEP8 style guidelines
- Fix web scraper memory leak
- Make the web scraper more robust
- Migrate to Angular
- Add Command-Line Arguments for Web Scraper
- Discuss Integration with the Canvas API
- Migrate models and schemas to SQLModels
- Overhaul Scraping Backend
- Improve AgTern CLI
- Implement CI/CD Pipeline with Kubernetes and GitHub Actions